PostgreSQL with Local Small Language Model and In-Database Vectorization | Azure
Improve search capabilities for your PostgreSQL-backed applications using vector search and embeddings generated in under 10 milliseconds without sending data outside your PostgreSQL instance. Integrate real-time translation, sentiment analysis, and advanced AI functionalities securely within your database environment with Azure Local AI and Azure AI Service. Combine the Azure Local AI extension with the Azure AI extension to maximize the potential of AI-driven features in your applications, such as semantic search and real-time data translation, all while maintaining data security and efficiency.

Joshua Johnson, Principal Technical PM for Azure Database for PostgreSQL, demonstrates how you can reduce latency and ensure predictable performance by running locally deployed models, making it ideal for highly transactional applications.
Transform your PostgreSQL app’s performance.
Precise, relevant results for complex queries.

Enhance search accuracy with semantic search and vector embeddings. Start here.
Leverage Azure local AI and Azure AI Service together.

Watch our full video here:
QUICK LINKS:
00:00 — Improve search for PostgreSQL
01:21 — Increased speed
02:47 — Plain text descriptive query
03:20 — Improve search results
04:57 — Semantic search with vector embeddings
06:10 — Test it out
06:41 — Azure local AI extension with Azure AI Service
07:39 — Wrap up
Link References
Check out our previous episode on Azure AI extension at https://aka.ms/PGAIMechanics
Get started with Azure Database for PostgreSQL — Flexible Server at https://aka.ms/postgresql
To stay current with all the updates, check out our blog at https://aka.ms/azurepostgresblog
Unfamiliar with Microsoft Mechanics?
As Microsoft’s official video series for IT, you can watch and share valuable content and demos of current and upcoming tech from the people who build it at Microsoft.
- Subscribe to our YouTube: https://www.youtube.com/c/MicrosoftMechanicsSeries
- Talk with other IT Pros, join us on the Microsoft Tech Community: https://techcommunity.microsoft.com/t5/microsoft-mechanics-blog/bg-p/MicrosoftMechanicsBlog
- Watch or listen from anywhere, subscribe to our podcast: https://microsoftmechanics.libsyn.com/podcast
Keep getting this insider knowledge, join us on social:
- Follow us on Twitter: https://twitter.com/MSFTMechanics
- Share knowledge on LinkedIn: https://www.linkedin.com/company/microsoft-mechanics/
- Enjoy us on Instagram: https://www.instagram.com/msftmechanics/
- Loosen up with us on TikTok: https://www.tiktok.com/@msftmechanics
Video Transcript:
-You can now improve search for your Postgres-backed application and take advantage of vector search, generating vector embeddings in under 10 milliseconds, all without the need to send data outside of your Postgres instance.
-In fact, vectors are core to the generative AI experience where words and data are broken down into coordinate-like values, and the closer they are in value, the more similar they are in concept. As you submit prompts, those are broken down into vectors and used to search across data stored in the database to find semantic matches.
-And now in addition to the Azure AI extension that we showed before where we make a secure API call to the Azure OpenAI service and then transmit data via the Azure AI extension to generate vector embeddings with the ADA model, you now have a new option with the Azure local AI extension that lets you generate embeddings without your data ever leaving the server.
-This is made possible by running a purpose-built small language model called multilingual-E5-small developed by Microsoft Research. It runs on the Onyx Runtime inside the same virtual machine as your Postgres database to generate vector embeddings without transmitting your data outside of your Postgres server instance. The biggest benefit to using locally deployed models is the decrease in latency from calls to a model hosted remotely.
-It also makes timing and performance more predictable because you won’t hit query or token limits resulting in retries. Let me show you an example of how much this speeds things up. Here, I’ve created two SQL functions for local and remote embedding generation. Both are using the same data and the same dimension size of 384.
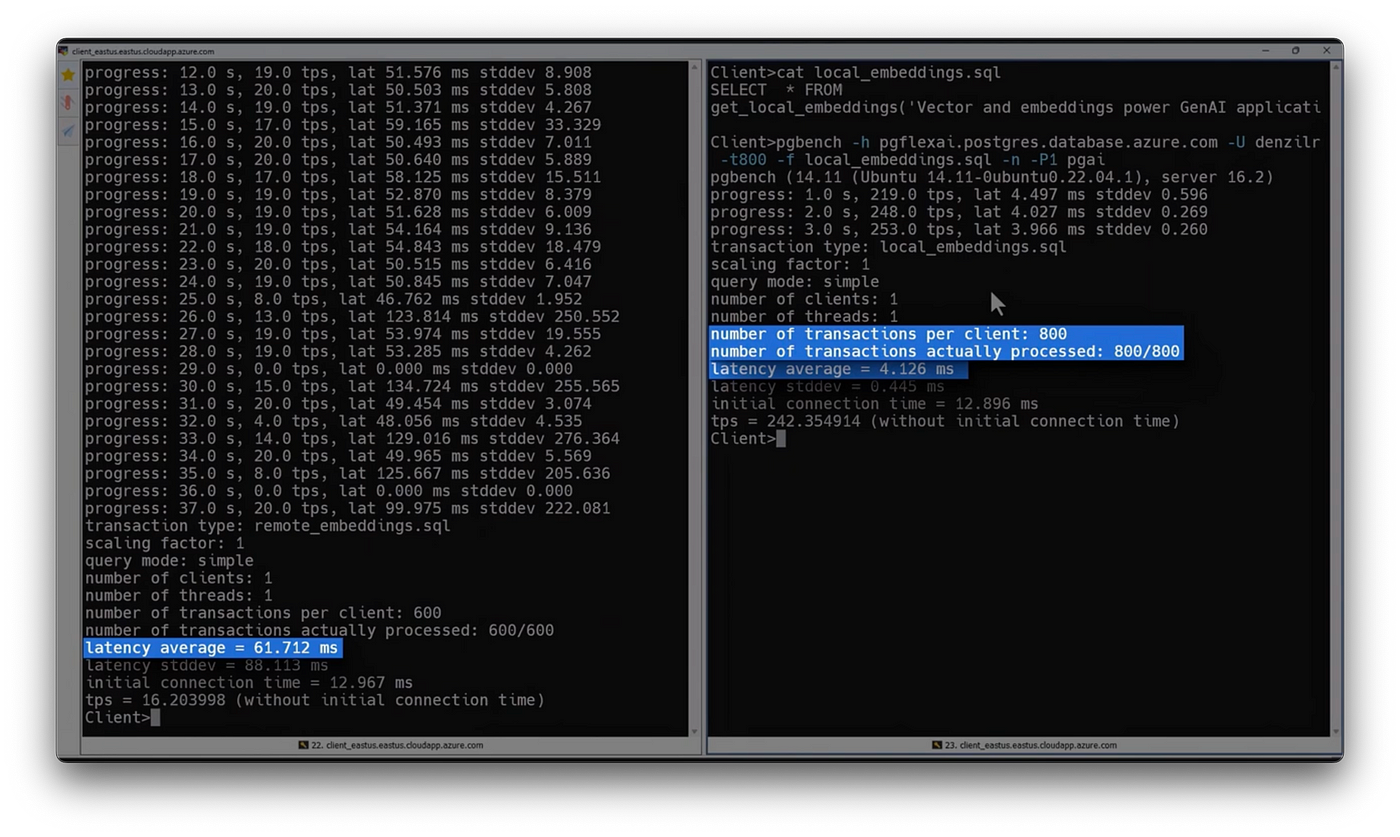
-And here, I have both ready to run side by side in pgbench. On the left, I’ll use the Azure AI extension to call the remote API to generate in return a vector embedding using the ADA 3 model running 600 transactions. On the right, I’ll use local in database embeddings to generate in return of vector embedding with the multilingual-E5 model running 800 transactions.
-I’ll start by kicking off the remote API SQL function on the left. Then I’ll run the local embedding model on the right. This is going to run for more than 30 seconds, but I’ll speed things up a little to save time. As you can see, generating the embeddings locally on the right reduced average latency from around 62 milliseconds to four milliseconds, and I ran the 800 transactions in about three seconds.
-On the left, I ran 200 less transactions than I did using the local embeddings. This took 37 seconds versus three seconds, so we were also able to process 242 transactions per second locally versus just 16 transactions per second with a remotely hosted model and API. That makes using the local AI extension around 15 times faster, which makes it a great option for highly transactional applications like e-commerce apps, ticketing systems, or even to run your chatbot knowledge bases and others.
-Let me show you how you can apply vector search and gen AI using our sample hotel booking app. First, I’ll show the experience without vectors, so you can see the true difference in experience. I’ll start with a plain text descriptive query to find properties in Seattle near the Space Needle with three bedrooms that allow pets.
-This is using a few built-in Postgres capabilities to drive some of the semantic meaning and keywords in the query with keyword and like clauses. You’ll see that using the full text search returns zero results, so it didn’t work for this complex prompt. So let me try another traditional approach. I’ll move to pgAdmin to see what happens if I manually extract the keywords.
-If we expand the query a bit by adding an OR clause with the keywords for the landmark we’re interested in seeing, Space Needle, we get over 100 results, but we can see from the descriptions that they’re not useful. For example, a few listings are way too small for three bedrooms, like a micro studio on Capitol Hill with 175 square feet and a Queen Anne condo with 800 square feet.
-So let’s try one more thing to see if we can get closer without using vectors. If you’ve been using Postgres for a while, you’ll know that it has two custom data types, tsvector, which sounds a lot like vector search, and tsquery to support full text search to match specific words or phrases within text data.
-I’ve added a column for tsvector in our listings table to document word or numbers in our descriptions, and here’s what that looks like. As you’ll see in the text search column, it’s converted longer strings into individual words segments, and I’ve added both GIN and GIST indexes for tsquery, which provides support for a combination of Boolean operators.
-These two modifications might allow for a natural language search like ours. That said, the best I can do is modify my query to just Space Needle and three bedrooms, and the result is better than zero, but it doesn’t have everything I need because I had to remove the pets allowed and proximity elements from my search.
-The search phrase is just too complicated here. To make this work, we would need to create additional indexes, assign weights to different parts of the input text for relevance ranking, and probably modify the search phrase itself to limit the number of key items that we’re looking for. So it would no longer be natural language search, so traditional methods fall short.
-But the good news is we can make all of this work using semantic search, with vector embeddings generated locally with an Azure Postgres thanks to the Azure local AI extension. Let me show you. First, we need to convert our text data from the descriptions, summaries, and listing names into vectors, which will create multiple numeric representations for each targeted field in the database. Here, I’m adding a vector column, local_description_vector, to specify that all embeddings generated for this column will use my locally deployed model.
-And this is what the output of one row looks like. As I scroll to the right, you’ll see these are all vector dimensions. Now, we also need to do the same for the incoming search prompts. Here, the number of embeddings generated per field or user prompt is defined by the number of dimensions the model requires to provide an accurate representation of that data. This is my query to convert the prompt into vectors, and this is an example of the generated vector embeddings for that prompt.
-And depending on the embedding model, these can generate hundreds or thousands of dimensions per entry to retrieve similarity matches. So our vectors are now ready. And next, we’ll add an index to speed up retrieval. I’ve added an HNSW vector index to build a multi-layered graph, and I’ve specified cosign similarity, which is best suited for text and document search.
-And now with everything running using vector search with our local AI extension, let’s test it out. I’ll use the same verbose query from before in our hotel booking site, properties in Seattle near the Space Needle with three bedrooms that allow pets, and you’ll see that there are a number of results returned that meet all of the criteria from the natural language text. I can see from each description that they are near or have a view of or are a short walk to the Space Needle. Each clearly has three or more bedrooms and all of them allow for pets with different conditions.
-Of course, the Azure local AI extension can still work in tandem with the broader Azure AI service via the Azure AI extension, which lets me hook into more advanced capabilities including language translation, vision, speech, and sentiment analysis, as well as generative AI chat with large language models in the Azure OpenAI service. In fact, let’s combine the power of both the Azure AI and Azure local AI extensions to perform realtime translations of listing summaries for the properties that meet our requirements.
-I’ve enabled the Azure AI extension, and in my SELECT statement, you’ll see that I’m using the Azure Cognitive Translate API for ES or Spanish for listing summaries. Now, I’ll go ahead and select all these lines and run it. I’ll adjust the view a little bit, and when I pull up the map view and open the geometry viewer, you’ll see that I have both the original English summary, and below that, the Spanish summary.
-And to see more of what’s possible with the Azure AI extension, check out our previous episode at aka.ms/pgaaimechanics. So that’s how you can improve search using vectors without sending data outside of your database to generate embeddings while dramatically reducing latency and still take advantage of the broader Azure AI service stack.
-To get started with Azure Database for PostgreSQL — Flexible Server, check out aka.ms/postgresql. And to stay current with all the updates, check out our blog at aka.ms/azurepostgresblog. Keep watching Microsoft Mechanics for the latest updates. Hit Subscribe and thank you for watching.
